How to use the catalog

To follow along with this tutorial interactively, you can either clone this repository and follow the provided instructions to run the catalog_tutorial.ipynb notebook, or directly access a cloud-hosted Jupyter notebook by clicking the above Binder button (with the necessary conda environment set up automatically for you!). Note that if you clone the repository yourself, the environment.yml file found in the repository is crucial to loading up these hdf5 files; otherwise you may run into package conflicts.
In this tutorial, we will showcase both the catalog structure, and provide some examples of how you can take advantage of the pandas.DataFrame format to fill in desired info for each AR, with ease!
Catalog Structure¶
import pandas as pd
import xarray as xr
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
from notebook_files.catalog_display import display_catalogThe catalog files are organized by year, from 1980 until 2022. For this tutorial, we only look at the 2022 data. Each year’s file is an .hdf5 file, that, once loaded, consists of a pandas.DataFrame. Let’s load up the storms from 2022, and take a look at the output.
storms = pd.read_hdf('./notebook_files/2022_storm_df.h5')Each row consists of an AR storm event.
There are two columns in the dataframe, data_array and is_landfalling.
data_arrayis a binary mask for that particular AR event in that row, in the form of an xArray DataArrayis_landfallingindicates whether that storm ever makes landfall over the Antarctic ice sheet
First, let’s display the catalog using the custom display_catalog function. This function behaves like DataFrame.head(), which shows the first many rows of the DataFrame, where in the data_array column we specifically show thumbnails of the footprint of the storm at the time of its greatest spatial extent (instead of showing a string representation of an xarray.DataArray, yuck!)
# don't run this, it will take a while and spit out gibberish!
# storms.head(10)display_catalog(storms, 10)Let’s look at one of these DataArrays.. For instance, the AR that caused the 2022 Antarctic Heatwave..
storms.data_array.iloc[36]Let’s look at a visualization of this storm’s footprint, at a particular point in time.
storms.data_array.iloc[36].isel(time=20).plot.imshow();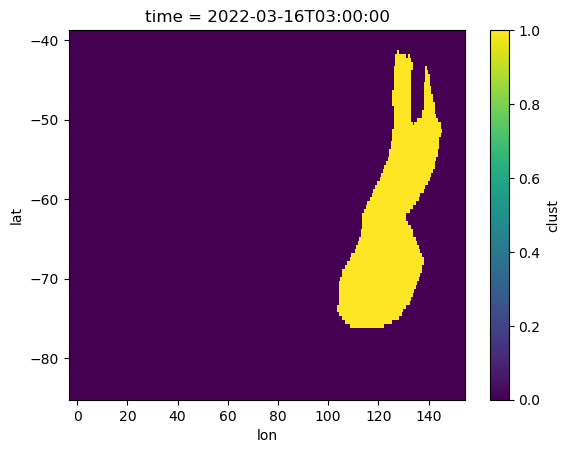
What if we just want to look at landfalling storms?
# first 20 storms of landfalling storms of 2022
display_catalog(storms[storms.is_landfalling], 10)# input to display_catalog must always be a dataframe, no series!
display_catalog(storms.iloc[[100]], 20)What can we do with such a catalog?¶
1. Get start, end dates, and total storm duration¶
def compute_duration(ar_da):
days = (ar_da.time.max() - ar_da.time.min()).values.astype('timedelta64[h]').astype(int) + np.timedelta64(3, 'h')
return days
def add_start_date(ar_da):
start = ar_da.time.min().values
return start
def add_end_date(ar_da):
end = ar_da.time.max().values
return endstorms['duration'] = storms['data_array'].apply(compute_duration)
storms['start_date'] = storms['data_array'].apply(add_start_date)
storms['end_date'] = storms['data_array'].apply(add_end_date)display_catalog(storms, 10)2. Get storm areas¶
# compute maximum spatial extent of each storm in its lifetime
# grab area file
grid_areas = xr.open_dataset('./notebook_files/MERRA2_gridarea.nc')
grid_areas = grid_areas.sel(lat=slice(-86, -39)).cell_area
def compute_max_area(ar_da):
grid_area_storm = grid_areas.sel(lat=ar_da.lat, lon=ar_da.lon)
max_area = float(ar_da.dot(grid_area_storm).max().values/(1000**2))
return max_areastorms['max_area'] = storms['data_array'].apply(compute_max_area)display_catalog(storms, 10)3. Get any quantity you want from your favorite re-analysis product!¶
Each storm has an associated xarray mask in space and time.. use it to extract quantities from a reanalysis dataset of interest!